

背景











训练神经网络执行各种任务,例如识别物体、导航无人驾驶汽车、玩游戏,不仅会带来很高的计算功耗,也会花费很长时间。集成了成百上千个处理器的大型计算机通常需要学习这些任务,而训练时间会达到几周甚至数月。
那么,为什么会出现上述现象呢?
究其原因,还是要从经典的计算机体系结构:冯·诺依曼体系结构说起。冯·诺依曼体系结构是目前大多数计算机以及处理器芯片的主流架构。这种计算机体系结构是由美籍匈牙利科学家冯·诺依曼(John von Neumann)于1946年提出。
(图片来源:维基百科)
在冯·诺依曼体系结构中,存储器(内存)用于存储程序指令和数据;处理器(CPU)则用于执行指令与处理相关数据。然而,处理器与内存是完全分离的两个单元,数据需要在处理器与内存之间来回移动。随着计算机技术不断进步,处理器速度不断提高,内存容量也不断扩大,可是内存访问速度的增长却缓慢,成为了计算机整体性能的一个重要瓶颈,也就是所谓的“内存墙”问题。
采用冯·诺依曼体系结构的计算机,在训练神经网络时,需要展开大量计算,频繁读写内存,数据会在处理器与内存之间频繁地来回往复,这样会耗费大部分的能量与时间。
为了解决上述问题,“内存内计算(in-memory computing)”提供了一种非常有前途的解决方案。它在同一个器件上集成存储与计算功能,让内存不仅成为存储器,也成为处理器。这样一来,在内存中直接执行计算任务,大大提升计算机的整体性能与效率,大幅降低能耗,加快运行速度。
近年来,世界各国的科学家们展开了许多有望带来“内存内计算”的科研探索。笔者曾多次介绍过相关领域的科研突破,让我们先通过以“忆阻器”与“阻变式样存储器”为代表的科研案例来回顾一下:
(一)美国密西根大学的研究人员开发出一种新型忆阻器芯片,它能突破传统计算机体系结构所遭遇的瓶颈,更加适合人工智能机器学习系统,更好地应对复杂的大数据问题,功耗更低,速度更快。
(图片来源:密西根大学)
(二)法国国家科学研究院、波尔多大学与埃夫里大学的研究人员们联合开发出一种直接位于芯片上的人工神经突触,也称为“忆阻器”。这一研究成果让智能系统学习所需的时间与能量变得更少,并且是全自动的。
(图片来源: 法国国家科学研究院)
(三)美国密歇根大学开发出由忆阻器制成的神经网络系统,也称为储备池计算系统。它教会机器像人类一样思考,并显著提升效率。它可以避免大多数昂贵的训练过程,也为网络提供了记忆能力。
(图片来源:参考资料【2】)
(四)美国斯坦福大学团队曾开发出一种“三维芯片”,将存储器和逻辑单元,像楼板一样一层一层地交替放置,并采用成千上万的垂直纳米连接进行通信。这样缩短了数据传输的距离,让数据传输得更快,使用的电量更少。
(图片来源:斯坦福大学)
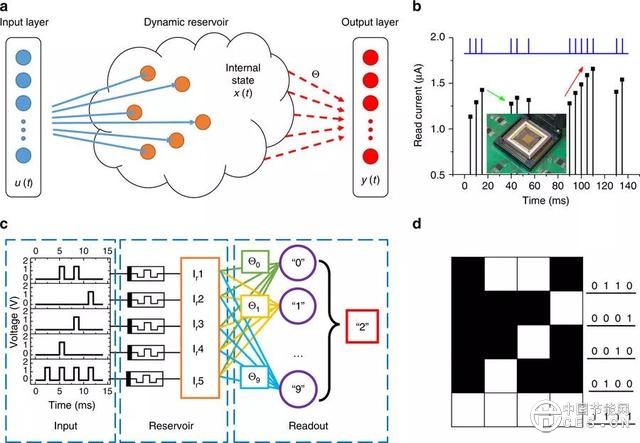
(五)美国普渡大学、国家标准与技术研究院以及泰斯研究公司的研究人员们合作设计出由二维材料二碲化钼制成的阻变式存储器(RRAM)。这种 RRAM 有望提供高速且省电的数据存储方式。
下图所示:基于2H-MoTe2- 和 2H-Mo1−xWxTe2- 的 RRAM 的表现以及根据薄片的厚度设置的电压。
(图片来源:参考资料【3】)
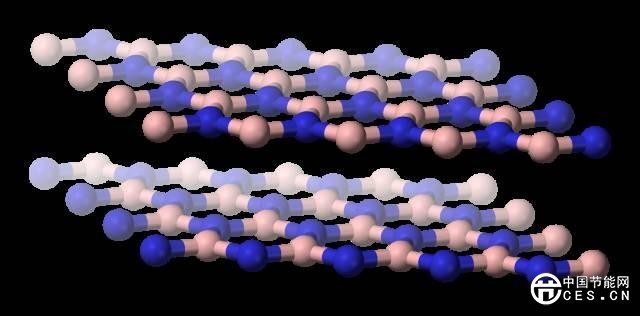
(六)中国苏州大学的研究人员多层六方氮化硼作为电介质,设计了一组“阻变式存储器(RRAM)”。这项研究有望带来比目前存储技术更加快速与节能的新存储技术。
六方氮化硼结构示意图(图片来源:维基百科)
(七)俄罗斯莫斯科物理技术学院(MIPT)的科研人员开发出一种新方案,能控制由原子层沉积(ALD)技术制备的钽氧化物薄膜中的氧含量,这种薄膜有望成为非易失性阻变式存储器的基础。
(图片来源:MIPT)
创新
今天,让我们来看一项有望带来“内存内计算”的新成果。
近日,美国加州大学圣迭戈分校的科研团队开发出一种神经启发的软硬件协同设计方案,这一方案将使得神经网络训练更加节能与快速。有朝一日,他们的工作将使得在低功耗设备例如智能手机、笔记本和嵌入式设备上训练神经网络变得可能。
下图所示:加州大学圣迭戈分校的一个科研团队开发的硬件与算法,将降低训练神经网络所需要的能耗与运行时间。
(图片来源:David Baillot/加州大学圣迭戈分校雅各布斯工程学院)
一篇近期发表在《自然通信(Nature Communications)》期刊上的论文描述了这项研究进展。
技术
加州大学圣迭戈分校雅各布斯工程学院电气与计算工程系教授、论文高级作者 Duygu Kuzum 及其实验室与 Adesto Technologies 公司合作开发出“可在内存单元中直接进行计算”的硬件与算法,无需反复地来回传递数据。
加州大学圣迭戈分校 Kuzum 研究小组的电气工程系博士生、论文第一作者 Yuhan Shi 表示:“我们正在从两端(设备端与算法端)解决这一问题,最大化神经网络训练时的能量效率。”
这项研究所用的硬件组件,是一种超级节能的非易失性存储器技术,即512千比特亚量子“导电桥式随机存取存储器(CBRAM)”阵列。
亚量子导电桥式随机存取存储器特性(图片来源:参考资料【4】)
CBRAM,是一种极具潜力的电阻式存储器技术,主要是利用记忆元件电阻之大小作为信息储存状态判读之依据,不同的电阻代表不同的储存状态,它在存取速度及能耗表现上具有极佳的表现,被视为最有潜力成为下一世代的非挥发性存储器元件之一。
(图片来源:加州大学圣迭戈分校雅各布斯工程学院)
亚量子导电桥式随机存取存储器阵列的功耗是如今领先的存储器技术的百分之一到十分之一。这种器件基于 Adesto 的 CBRAM 存储技术。这种技术主要用作只具有 “0”与“1”两种状态的数字存储器,但是 Kuzum 及其实验室的演示表明,这项技术可以通过编程而具有多个模拟状态,从而模仿人脑中的生物突触。这种所谓的“突触装置”能用于为神经网络训练展开“内存内计算”。
Kuzum 在加州大学圣迭戈分校机器集成计算与安全中心工作,她领导开发了可简单映射到这种神经突触器件阵列上的算法。在神经网络计算期间,这种算法节约了较多的能量与时间。
下图所示:从左到右,加州大学圣迭戈分校电气工程系博士生、论文第一作者 Yuhan Shi 以及加州大学圣迭戈分校电气与计算工程系教授、研究带头人 Duygu Kuzum。
(图片来源:加州大学圣迭戈分校雅各布斯工程学院)
该方案使用了一种节能的神经网络,称为“脉冲神经网络(spiking neural network)”,用于实现硬件中的无监督学习。最重要的是,Kuzum 的团队应用了另一种由他们开发的节能算法,称为“软剪枝(soft-pruning)”,它使神经网络训练更加节能,也不会在准确度上牺牲很多。
节能算法
神经网络是一系列互连的人工神经元层,每一层的输出为另一层提供输入。这些层之间连接的强度由所谓的“权重”代表。训练神经网络能对这些权重进行更新。
传统神经网络耗费许多能量来持续更新每一个权重。但是,在脉冲神经网络中,只有与脉冲神经元相关联的权重才会得到更新。这意味着更少的更新,也意味着更少的计算功耗和时间。
神经网络也展开所谓的“无监督学习”。“无监督学习”意味着它可以从根本上进行自我训练。例如,如果将一系列手写数字展示给神经网络,神经网络将搞清楚如何区分0、1、2等。这么做的好处是,神经网络无需通过标记的样本来训练,意味着它无需被告知它正看到 0、1、2,这对于导航等自主应用来说很有用。
为了训练得更快更节能,Kuzum 实验室开发出一种新算法,他们称为“软剪枝”,配合无监督的脉冲神经网络。“软剪枝”,是一种可以找到在训练期间已经成熟的权重,然后将它们设置为非零常数。这样就阻止了它们在剩余的训练中继续更新,从而最小化计算功率。
“软剪枝”,不同于传统的剪枝方法,因为它是在训练期间实现的,而不是在训练之后。当神经网络将它的训练放在测试中时,“软剪枝”也能带来更高的准确度。通常在剪枝中,冗余或者不重要的权重会被完全删除掉。负面影响是,你修剪的权重越多,神经网络在测试时的准确度就越低。但是“软剪枝”却能在低能量条件下保留住这些权重,所以它们仍然帮助神经网络以较高的准确度执行任务。
测试软硬件协同设计
团队在亚量子CBRAM 神经突触器件阵列上 ,实现了神经启发的无监督脉冲神经网络以及“软剪枝”算法。然后,他们训练这种神经网络从 MNIST 数据库中分类手写数字。
Yuhan Shi 安装突触器件进行测试(图片来源:加州大学圣迭戈分校雅各布斯工程学院)
在测试中,达75%的权重得到“软剪枝”,神经网络分类数字准确度达93%。相比而言,采用传统的修剪方法,仅40%的权重得到修剪,神经网络的准确度低于90%。
价值
Kuzum 表示:“传统处理器中的片上存储器非常有限,所以它们没有足够的能力在同一芯片上同时进行计算与存储。但是,在这种方案中,我们拥有了能在存储器中展开神经网络训练相关计算的大容量存储器阵列,无需将数据传输至外部处理器。在训练期间,这将带来许多性能增益并降低能耗。”
就节能而言,团队估计,相比于目前工艺水平,他们的神经启发软硬件协同方案能最终消减神经网络训练器件的能耗达两到三个数量级。
Kuzum 表示:“如果我们参照其他相似的存储技术来检测新硬件,我们估计我们器件的能耗能降低到百分之一至十分之一,然后我们的协同设计算法又将能耗再降低到十分之一。总的来说,我们希望遵循我们的方法,将能耗降低到千分之一至百分之一。”
未来
展望未来,Kuzum 和她的团队计划与存储技术公司合作,将这项工作推进到下一阶段。
他们的最终目标是开发一个完整系统,在这个完整系统中,神经网络可以在存储器中得到训练,从而以更低的功耗与更少的时间预算,完成更复杂的任务。




